一、MINIX 文件系统
minix文件系统和unix的文件系统基本相同。它是由6个部分组成。
360KB软盘文件系统,整个磁盘被划分为1KB大小的磁盘块,每一个磁盘块对应一个逻辑块号。因此图中共有360个磁盘块,也即360个逻辑块号。(后面说的磁盘块和逻辑块等效)
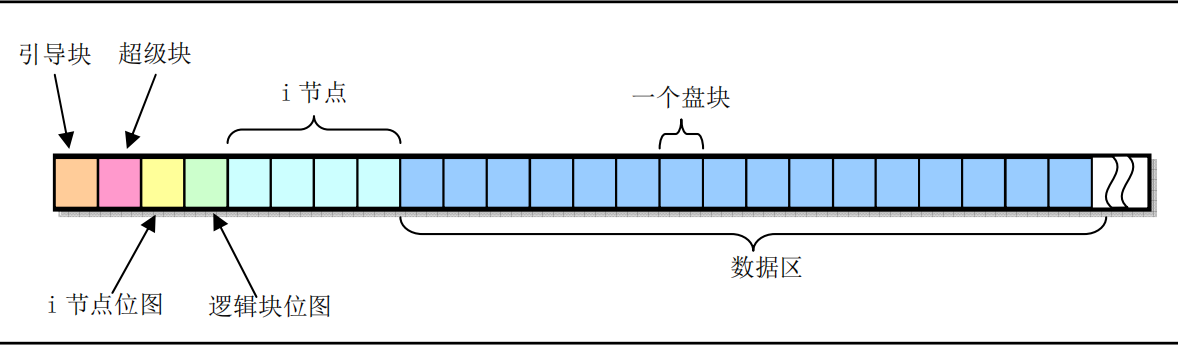
数据区:用于表示文件数据的区域,其中每一逻辑块都有一个逻辑块号。
逻辑块位图:用于表示数据区的每一个逻辑块的使用情况。占用一个逻辑块,也即1024byte,,也即可以表示8192个逻辑块的使用情况,但是第一个bit位不使用,所以表示8191个逻辑块。当逻辑块为1KB,逻辑位图占用一块时,最多可以表示数据区8MB大小内存(理论情况),所以360KB的软盘,只保存一个文件,360 - (引导块 + 超级快 + i节点位图(1)+ 逻辑块位图(1)+ i节点(1))= 355块,那么这个文件最大可以355KB 。1表示使用、0表示未使用。(第一位不用会系统会设置为1,因为没有找到空闲块时会返回0,如果第一位使用的话,会导致返回0表示第一个块可以使用,导致异常)。
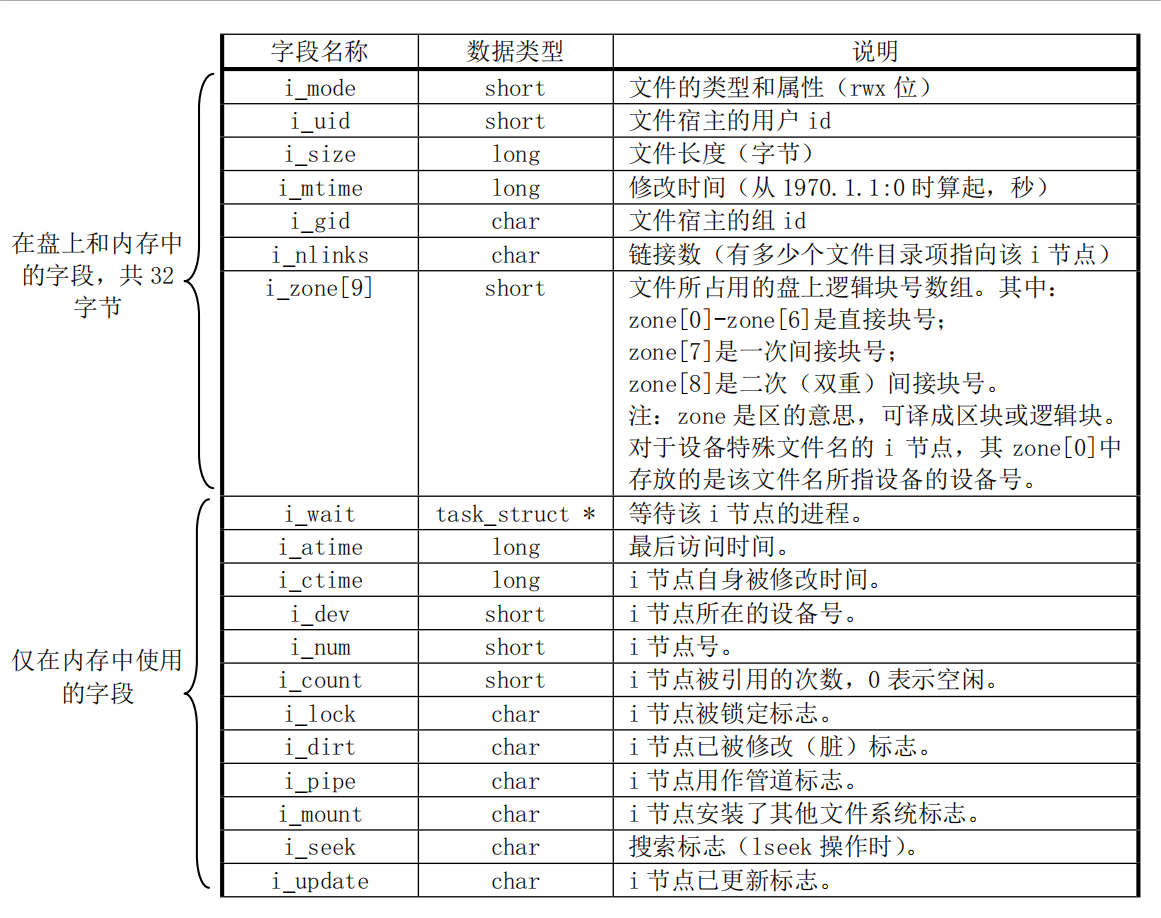
inode节点:用于表示一个文件的信息,一个inode节点占用32byte,所以一块可以表示32个inode节点。一个inode节点的数据保存在i_zone[9]数组中,0-6表示直接块号(7个块),7表示一次间接号(512个块,一个块1024byte,而一个块指针2byte,所有一个块可以有512个块指针),8表示二次间接号(512*512个块)。所以一个inode节点也即一个文件最多可以有262663个块(理论情况,对于360KB软盘最多只有360个块),所以文件最大为256MB。 如下图:
inode位图:用于表示inode节点的使用情况。同逻辑块位图一样。
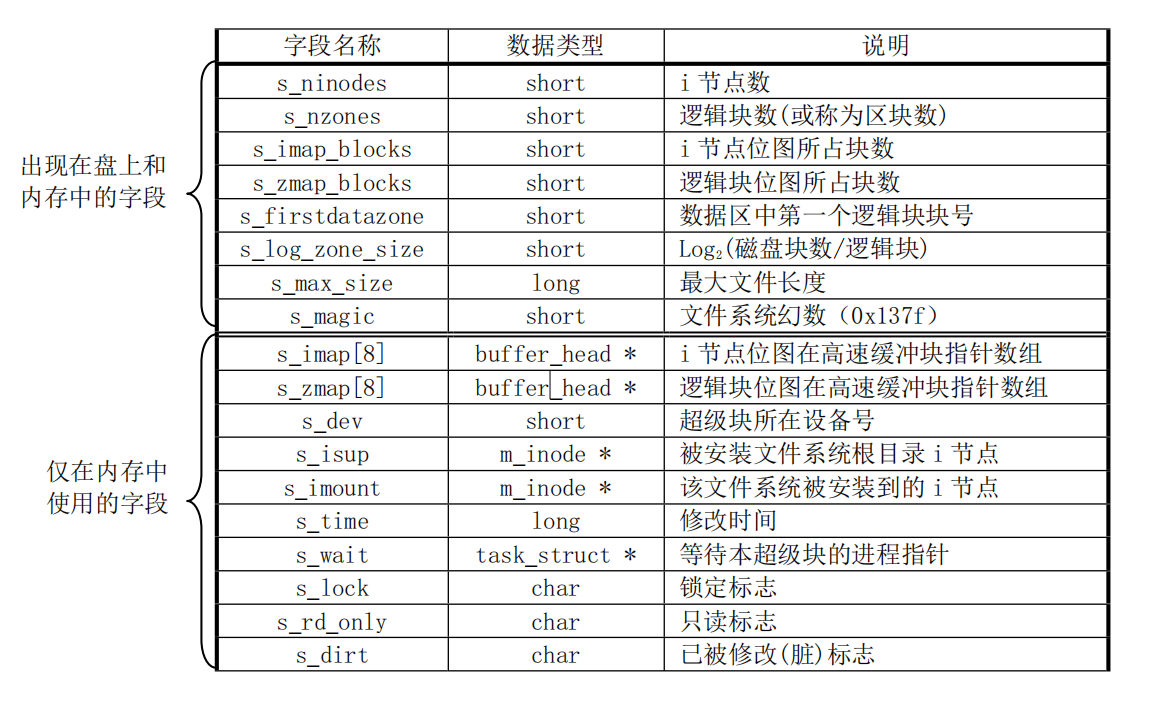
超级快:用于表示各个元数据的元数据信息。定义了总的inode节点数量、总的逻辑块数量、inode节点位图、逻辑块位图占用的块数量、数据区第一个逻辑块号(因为逻辑位图的第一个bit位,表示的是数据区第一块的使用情况,即是相对数据区的块号,而不是从磁盘开始的块号)、最大文件长度(理论值4GB),逻辑位图最多占用8个块,所以在Linux0.11中,最多可以表示的文件大小为64MB,最大可以支持的块设备容量为64MB(也可以根据块数short占用2字节计算)。如下图:
引导块:引导启动、存储元数据和文件系统验证等重要功能。
二、Linux 0.1.1内存的表示
在Linux系统中,使用了高速缓存来保存磁盘的数据、以加快性能。

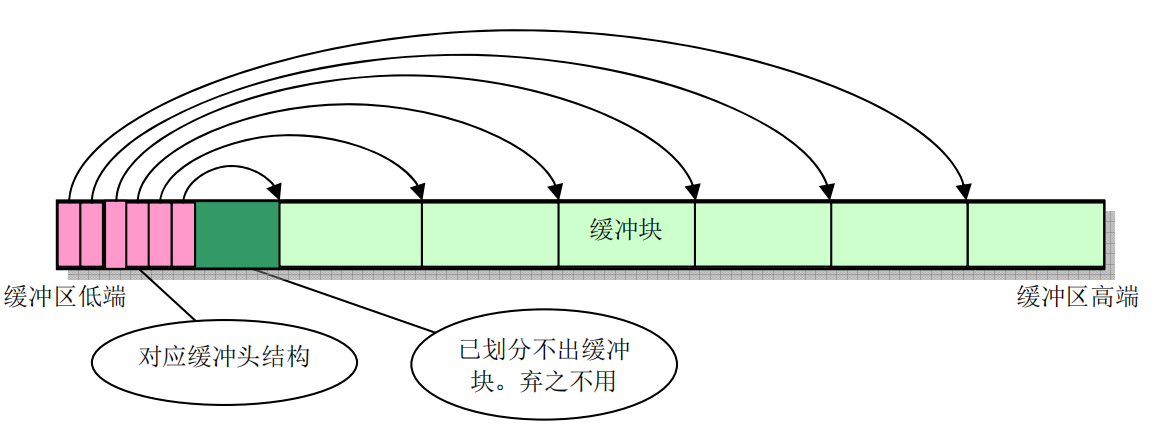
同样的道理,Linux系统中,假设有16 MB内存,将1MB-4MB之间的内存分割为同磁盘块1KB大小一样的缓存块,使用end--640K之间的内存来表示缓存块的使用情况。
buffer_head:表示缓存头信息,即每个缓存块的使用情况。以后系统需要访问磁盘时,都会通过一个buffer_head结构来和磁盘打交道,如果当前缓存中没有要访问的块号,则会找到一个缓存块来加载磁盘块信息,下次访问时,会直接使用这个缓存块进行crud。

缓存块头的初始化:
1// buffer_end = 4MB2void buffer_init(long buffer_end)3{4 struct buffer_head * h = start_buffer;5 void * b;6 int i;7 if (buffer_end == 1<<20)8 b = (void *) (640*1024);9 else10 b = (void *) buffer_end;11 while ( (b -= BLOCK_SIZE) >= ((void *) (h+1)) ) {12 h->b_dev = 0; // 使用该缓冲块的设备号13 h->b_dirt = 0; // 脏标志,即缓冲块修改标志14 h->b_count = 0; // 缓冲块引用计数15 h->b_lock = 0; // 缓冲块锁定标志16 h->b_uptodate = 0; // 缓冲块更新标志(或称数据有效标志)17 h->b_wait = NULL; // 指向等待该缓冲块解锁的进程18 h->b_next = NULL; // 指向具有相同hash值的下一个缓冲头19 h->b_prev = NULL; // 指向具有相同hash值的前一个缓冲头20 h->b_data = (char *) b; // 指向对应缓冲块数据块(1024字节)21 h->b_prev_free = h-1; // 指向链表中前一项22 h->b_next_free = h+1; // 指向连表中后一项23 h++; // h指向下一新缓冲头位置24 NR_BUFFERS++; // 缓冲区块数累加25 if (b == (void *) 0x100000) // 若b递减到等于1MB,则跳过384KB26 b = (void *) 0xA0000; // 让b指向地址0xA0000(640KB)处27 }28 h--; // 让h指向最后一个有效缓冲块头29 free_list = start_buffer; // 让空闲链表头指向头一个缓冲快30 free_list->b_prev_free = h; // 链表头的b_prev_free指向前一项(即最后一项)。31 h->b_next_free = free_list; // h的下一项指针指向第一项,形成一个环链32 // 最后初始化hash表,置表中所有指针为NULL。33 for (i=0;i<NR_HASH;i++)34 hash_table[i]=NULL;35}
三、Linux 0.1.1文件操作
结构体
x1//表示打开的文件2struct file {3 unsigned short f_mode;4 unsigned short f_flags;5 unsigned short f_count; //使用量6 struct m_inode * f_inode; //保存文件数据信息7 off_t f_pos; //当前位置8};9
10//系统文件缓存11struct file file_table[NR_FILE]; // 文件表数组(64项)12
13//文件夹对象,的inode节点保存的都是子文件/文件夹对应的inode号和名称14//一个块1024byte,可以保存64个dir_entry15struct dir_entry {16 unsigned short inode;17 char name[NAME_LEN];18};xxxxxxxxxx141//表示一个进程对象2struct task_struct {3 long state; /* -1 unrunnable, 0 runnable, >0 stopped */4 long counter;5 unsigned long start_code,end_code,end_data,brk,start_stack;6 struct m_inode * pwd;7 struct m_inode * root;8 struct file * filp[NR_OPEN];//进程打开的文件9/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */10 struct desc_struct ldt[3];11/* tss for this task */12 struct tss_struct tss;13 ...14};
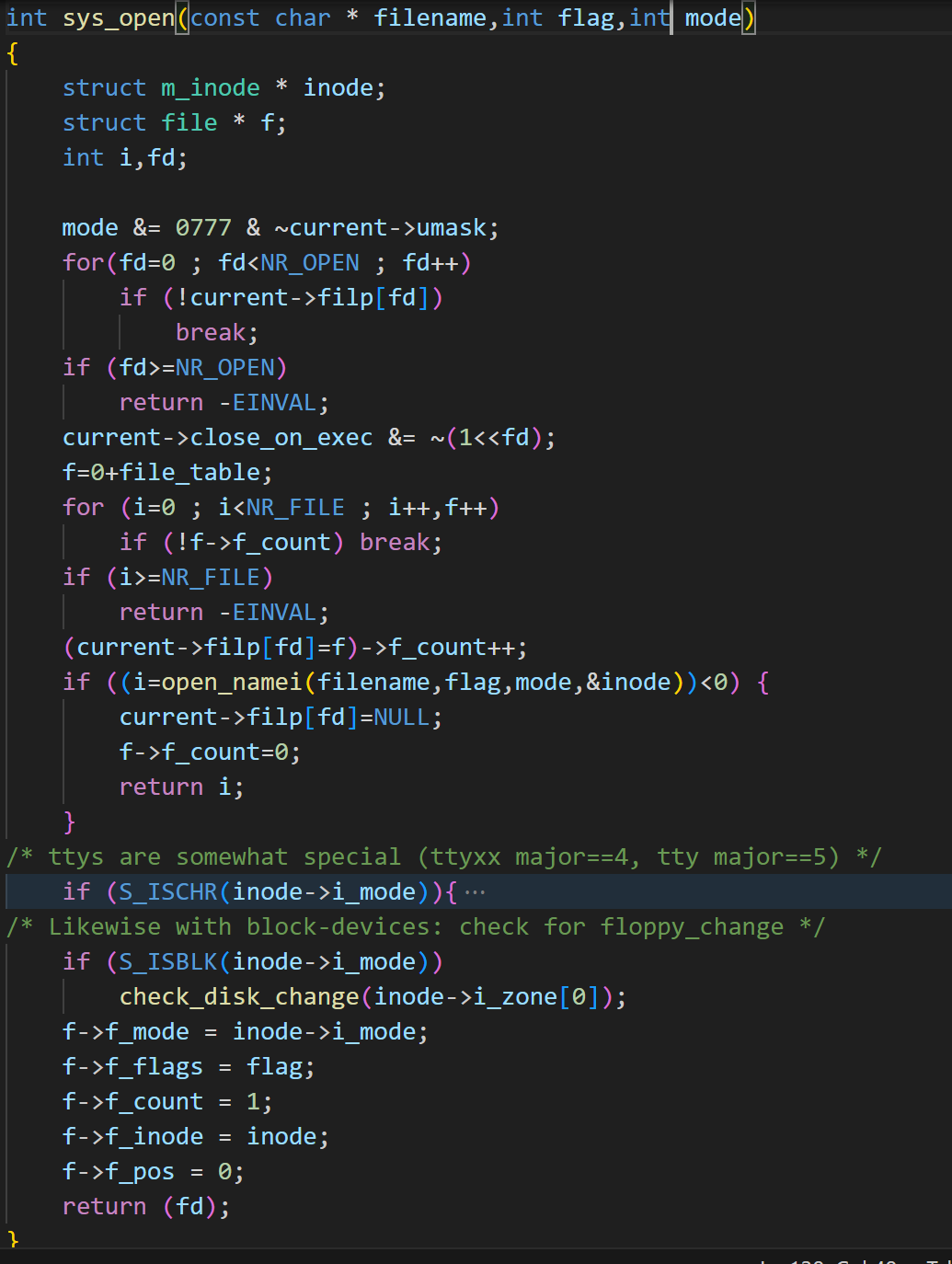
1)sys_open
xxxxxxxxxx61//打开(或创建)文件系统调用。2//参数3//filename文件名4//flag打开文件标志,它可取值:O_RDONLY(只读)、O_WRONLY(只写)或O_RDWR(读写),以及O_EXCL(被创建文件必须不存在)、O_APPEND(在文件尾添加数据)等其他一些标志的组合。5//mode指定文件的许可属性。这些属性有S_IRWXU(文件宿主具有读、写和执行权限)、S_IRUSR(用户具有读文件权限)、S_IRWXG(组成员具有读、写和执行权限)等等6int sys_open(const char * filename,int flag,int mode)文件打开的逻辑:文件路径/usr/src/linux
根据task_struct结构的filp属性,找到进程中没有使用的一个fd,即filp数组文件索引下标。
file_table数组中,找一个没有使用的文件file
关联filp[fd] = file
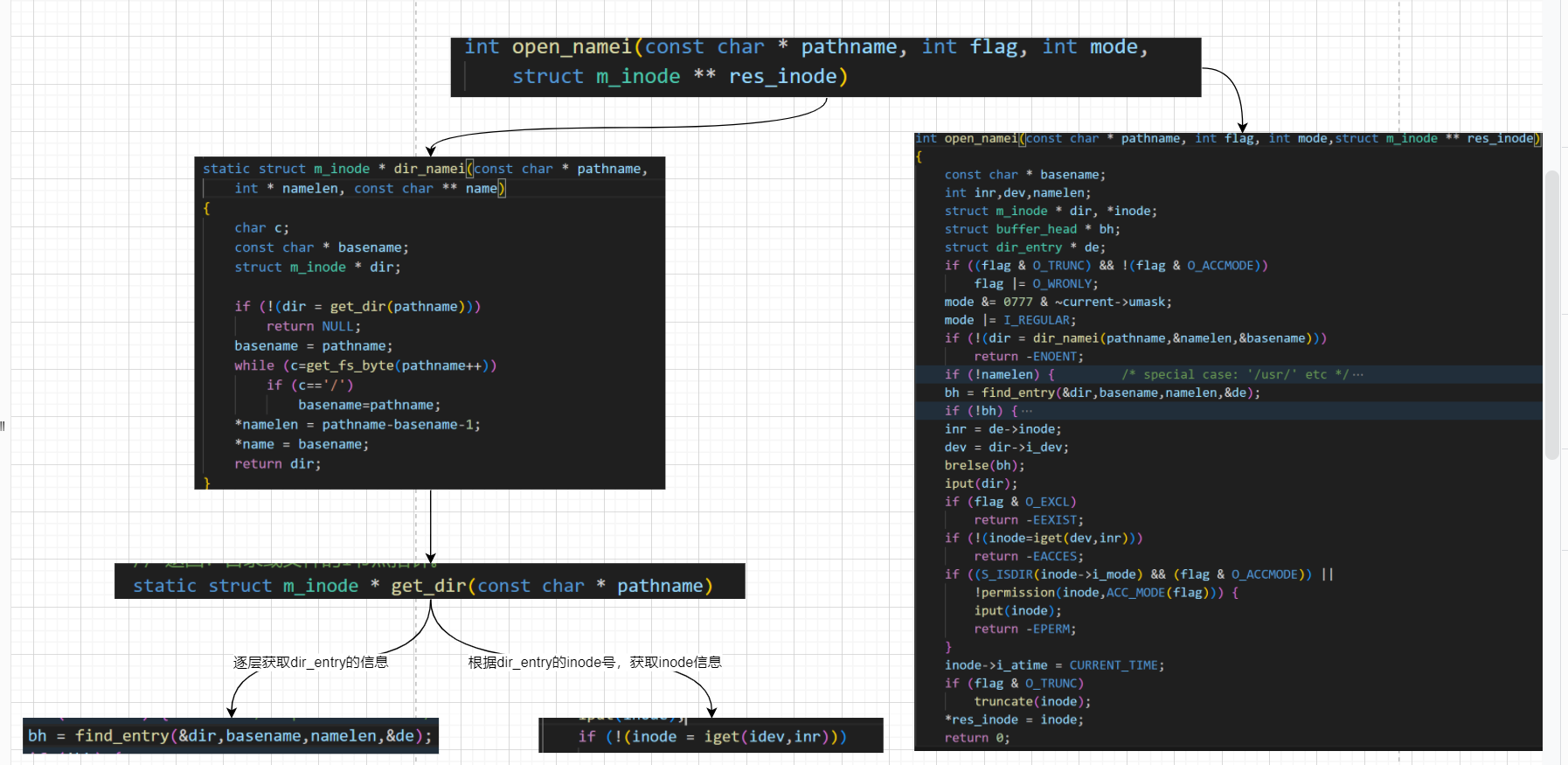
调用open_namei打开文件,并获取m_inode信息。使用dir_namei->get_dir获取到src文件的m_inode信息,最后根据find_entry获取linux的dir_entry信息,调用iget获取inode信息,并设置返回。
设置file的属性,最后返回fd。
2)sys_read
xxxxxxxxxx271// 读文件系统调用2// 参数fd是文件句柄,buf是缓冲区,count是预读字节数3int sys_read(unsigned int fd,char * buf,int count)4{5 struct file * file;6 struct m_inode * inode;7 if (fd>=NR_OPEN || count<0 || !(file=current->filp[fd]))8 return -EINVAL;9 if (!count)10 return 0;11 verify_area(buf,count);12 inode = file->f_inode;13 if (inode->i_pipe)14 return (file->f_mode&1)?read_pipe(inode,buf,count):-EIO;15 if (S_ISCHR(inode->i_mode))16 return rw_char(READ,inode->i_zone[0],buf,count,&file->f_pos);17 if (S_ISBLK(inode->i_mode))18 return block_read(inode->i_zone[0],&file->f_pos,buf,count);19 if (S_ISDIR(inode->i_mode) || S_ISREG(inode->i_mode)) {20 if (count+file->f_pos > inode->i_size)21 count = inode->i_size - file->f_pos;22 if (count<=0)23 return 0;24 return file_read(inode,file,buf,count);25 }26 return -EINVAL;27}文件读取的逻辑:fd为open函数返回的/usr/src/linux的索引下标
current->filp[fd],获取到当前进程的文件对象file
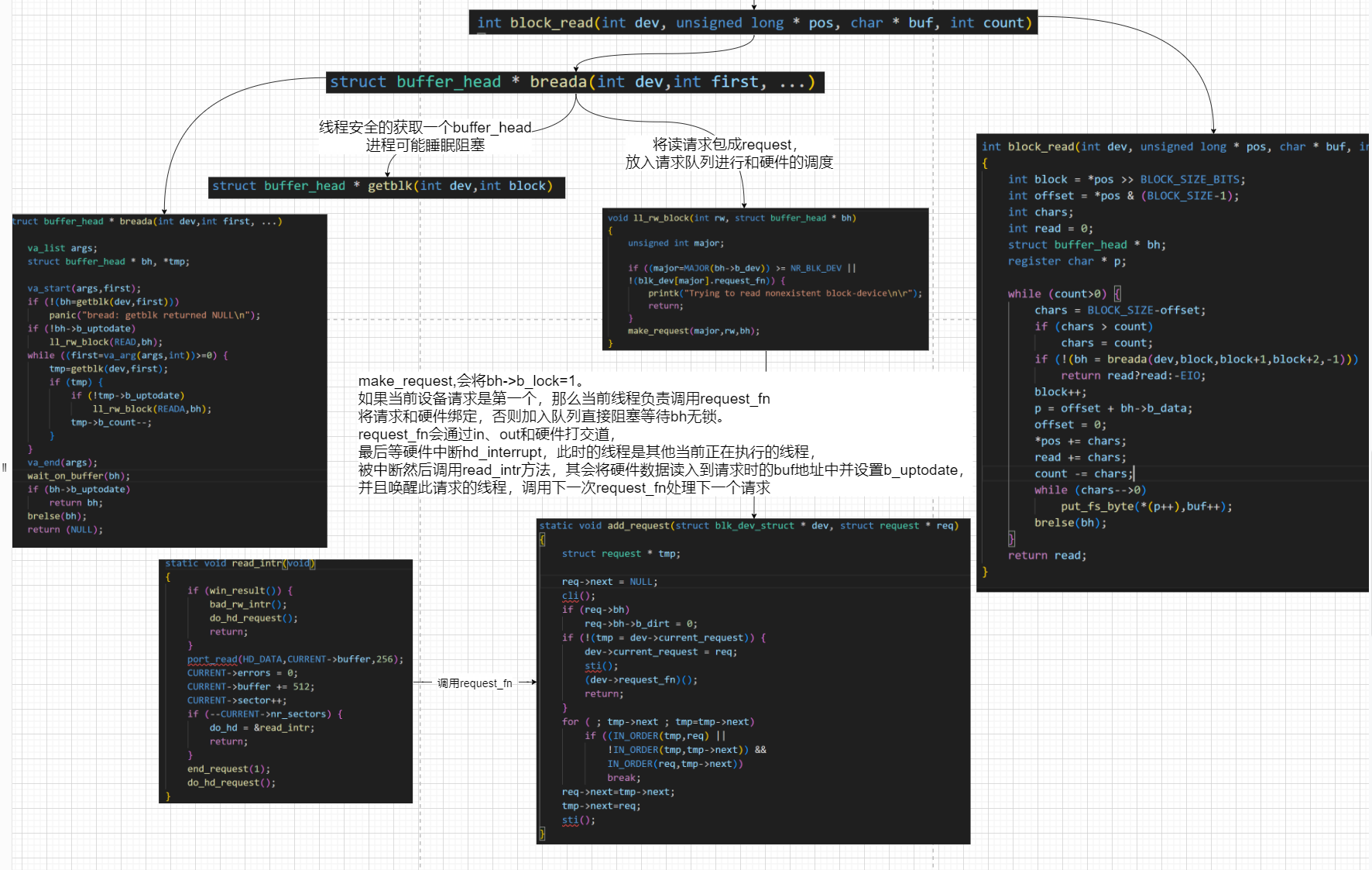
通过判断文件的类型,执行不同的读取操作,以块设备block_read为例。
获取buffer_head,将读请求封装成为request,加入请求队列
将buffer_head的lock标志设置为1,阻塞等待数据
第一个等待队列线程负责调用request_fn方法
硬件中断处理会调用read_intr方法,将读取到的数据复制到buffer_head中
如果还有数据要读取,继续调用request_fn,硬中断会继续执行read_intr方法
所有数据都完成时,唤醒等待的线程
3)sys_write
xxxxxxxxxx211//// 写文件系统调用2// 参数fd是文件句柄,buf是用户缓冲区,count是欲写字节数。3int sys_write(unsigned int fd,char * buf,int count)4{5 struct file * file;6 struct m_inode * inode;7 if (fd>=NR_OPEN || count <0 || !(file=current->filp[fd]))8 return -EINVAL;9 if (!count)10 return 0;11 inode=file->f_inode;12 if (inode->i_pipe)13 return (file->f_mode&2)?write_pipe(inode,buf,count):-EIO;14 if (S_ISCHR(inode->i_mode))15 return rw_char(WRITE,inode->i_zone[0],buf,count,&file->f_pos);16 if (S_ISBLK(inode->i_mode))17 return block_write(inode->i_zone[0],&file->f_pos,buf,count);18 if (S_ISREG(inode->i_mode))19 return file_write(inode,file,buf,count);20 return -EINVAL;21}文件写的逻辑:fd为open函数返回的/usr/src/linux的索引下标
current->filp[fd],获取到当前进程的文件对象file
通过判断文件的类型,执行不同的读取操作,以块设备block_write为例。
获取buffer_head,一页一页的写,如果写入的数据少于一页则直接申请一页,否则多申请为下一次做准备。
将数据写入缓冲中,设置为脏即可
下次有使用这个缓存时,使用ll_rw_block会将其刷入磁盘。
xxxxxxxxxx321int block_write(int dev, long * pos, char * buf, int count)2{3 int block = *pos >> BLOCK_SIZE_BITS; // pos所在文件数据块号4 int offset = *pos & (BLOCK_SIZE-1); // pos在数据块中偏移值5 int chars;6 int written = 0;7 struct buffer_head * bh;8 register char * p;9
10 while (count>0) {11 chars = BLOCK_SIZE - offset; //计算一块中剩余字节数量12 if (chars > count)13 chars=count;14 if (chars == BLOCK_SIZE) 15 bh = getblk(dev,block);16 else17 bh = breada(dev,block,block+1,block+2,-1);18 block++;19 if (!bh)20 return written?written:-EIO;21 p = offset + bh->b_data;22 offset = 0;23 *pos += chars;24 written += chars; // 累计写入字节数25 count -= chars;26 while (chars-->0)27 *(p++) = get_fs_byte(buf++);28 bh->b_dirt = 1;29 brelse(bh);30 }31 return written;32}
四、Linux 2.6.0-NIO操作
结构体
poll_wqueues->poll_table_page->poll_table_entry->wait_queue_t
xxxxxxxxxx341//一次select/pool,对应一个结构2struct poll_wqueues {3 poll_table pt;// poll_wait注册等待事件4 struct poll_table_page * table; //页表5 int error;6};7
8//一次select/pool,对应一个或多个(一个大于对象长度超过一页时,会增加)9struct poll_table_page {10 struct poll_table_page * next;//下一项地址11 struct poll_table_entry * entry;//链表结构12 struct poll_table_entry entries[0];//数组结构13};14
15// 一个监听的fd,对应一个结构16struct poll_table_entry {17 struct file * filp;18 wait_queue_t wait;//能找到task_struct19 wait_queue_head_t * wait_address; //根据此可以从对应的fd的sk_sleep中移除20};21
22struct wait_queue_t {23 unsigned int flags;24 struct task_struct * task;25 wait_queue_func_t func;// 唤醒回调26 struct list_head task_list;27};28
29struct wait_queue_head_t {//fd的sk_sleep属性,可以根据task_list关联出wait_queue_t,之后唤醒等待线程30 spinlock_t lock;31 struct list_head task_list;32};33
34一个进程需要select/poll监听10个fd时,会创建一个poll_wqueues结构,在遍历每个fd时,会调用相应的pool方法,首先判断poll_table_page是否为空/或者大小是否超过一页(是则会新创建一个poll_table_page,将之前的设置为新的next节点)假设没有,最终会创建10个poll_table_entry,设置filp、wait、以及当前等待队列wait_address(对应fd的sk_sleep)1)sys_select
xxxxxxxxxx41//n 最大描述符2//inp 读事件、outp写事件、exp异常事件3//timeval 超时时间4sys_select(int n, fd_set __user *inp, fd_set __user *outp, fd_set __user *exp, struct timeval __user *tvp)调用链:sys_select()--->do_select()--->sock_poll()->tcp_poll()-->poll_wait()
例如要监听socket的事件,则需要将当前线程注册到对应socket的sock结构的sk_sleep链表上,等待事件发生时,唤醒线程
sys_select
xxxxxxxxxx171sys_select(int n, fd_set __user *inp, fd_set __user *outp, fd_set __user *exp, struct timeval __user *tvp)2{3 ...4 timeout = MAX_SCHEDULE_TIMEOUT;5 ...6 if (n < 0)7 goto out_nofds;8
9 // 最大fd为1024个10 max_fdset = current->files->max_fdset;11 if (n > max_fdset)12 n = max_fdset;13 ...14 ret = do_select(n, &fds, &timeout);15 ...16 return ret;17}do_select
xxxxxxxxxx271int do_select(int n, fd_set_bits *fds, long *timeout)2{3 struct poll_wqueues table;4 poll_table *wait;5 ...6 poll_initwait(&table); //初始化table7 wait = &table.pt;8 for (;;) {9 set_current_state(TASK_INTERRUPTIBLE); //可中断唤醒10 ...11 for (j = 0; j < __NFDBITS; ++j, ++i, bit <<= 1) {12 file = fget(i);13 if (file) {14 f_op = file->f_op;15 if (f_op && f_op->poll) //调用sock_poll16 mask = (*f_op->poll)(file, retval ? NULL : wait);17 ...18 }19 }20 ...21 __timeout = schedule_timeout(__timeout); //睡眠22 }23 __set_current_state(TASK_RUNNING);24
25 poll_freewait(&table);//移除注册的监听事件26 return retval;27}sock_poll
xxxxxxxxxx181static unsigned int sock_poll(struct file *file, poll_table * wait)2{3 struct socket *sock;4 sock = SOCKET_I(file->f_dentry->d_inode);5 return sock->ops->poll(file, sock, wait); //调用tcp_poll6}7
8unsigned int tcp_poll(struct file *file, struct socket *sock, poll_table *wait)9{10 unsigned int mask;11 struct sock *sk = sock->sk;12 struct tcp_opt *tp = tcp_sk(sk);13
14 poll_wait(file, sk->sk_sleep, wait); //回调wait方法即__pollwait,将当前线程加入sk->sk_sleep队列15 //检测sk,看事件是否已到达16 ...17 return mask;18}__pollwait
xxxxxxxxxx241void __pollwait(struct file *filp, wait_queue_head_t *wait_address, poll_table *_p)2{3 struct poll_wqueues *p = container_of(_p, struct poll_wqueues, pt);4 struct poll_table_page *table = p->table;5
6 if (!table || POLL_TABLE_FULL(table)) { //为空或超过一页,创建新的poll_table_page7 struct poll_table_page *new_table;8 new_table = (struct poll_table_page *) __get_free_page(GFP_KERNEL);9 new_table->entry = new_table->entries;10 new_table->next = table;11 p->table = new_table;12 table = new_table;13 }14
15 {16 struct poll_table_entry * entry = table->entry;17 table->entry = entry+1;18 get_file(filp);19 entry->filp = filp;20 entry->wait_address = wait_address;21 init_waitqueue_entry(&entry->wait, current); //设置wait_queue_t中的线程22 add_wait_queue(wait_address,&entry->wait); //加入对应fd的sk_sleep中23 }24}2)sys_poll
xxxxxxxxxx21// pollfd封装了fd和读写事件 nfds数量2asmlinkage long sys_poll(struct pollfd __user * ufds, unsigned int nfds, long timeout)调用链:sys_poll()--->do_poll()--->do_pollfd()--->sock_poll()->tcp_poll()-->poll_wait()
sys_poll
xxxxxxxxxx171asmlinkage long sys_poll(struct pollfd __user * ufds, unsigned int nfds, long timeout)2{3 struct poll_wqueues table;4 int fdcount, err;5 unsigned int i;6 struct poll_list *head; //将所有监听事件封装为一个链接7 struct poll_list *walk;8
9 poll_initwait(&table);10 fdcount = do_poll(nfds, head, &table, timeout);11 12 // 将准备好的事件,设置到入参中13 ...14 poll_freewait(&table); //移除监听15 return err;16}17
do_poll
xxxxxxxxxx221static int do_poll(unsigned int nfds, struct poll_list *list,2 struct poll_wqueues *wait, long timeout)3{4 int count = 0;5 poll_table* pt = &wait->pt;6
7 for (;;) {8 struct poll_list *walk;9 set_current_state(TASK_INTERRUPTIBLE); //设置可中断10 walk = list;11 while(walk != NULL) {12 do_pollfd( walk->len, walk->entries, &pt, &count);13 walk = walk->next;14 }15 ...16 if (count)17 break;18 timeout = schedule_timeout(timeout); //阻塞19 }20 __set_current_state(TASK_RUNNING); /设置运行21 return count;22}do_pollfd
由于file->f_op->poll(file, pwait);总是会传入pwait,而不像select的(f_op->poll)(file, retval ? NULL : wait); 如果前面一个有返回时,后面的直接全部不处理监听
xxxxxxxxxx291static void do_pollfd(unsigned int num, struct pollfd * fdpage,2 poll_table ** pwait, int *count)3{4 for (i = 0; i < num; i++) { //遍历fdpage,调用file->f_op->poll5 int fd;6 unsigned int mask;7 struct pollfd *fdp;8
9 mask = 0;10 fdp = fdpage+i;11 fd = fdp->fd;12 if (fd >= 0) {13 struct file * file = fget(fd);14 mask = POLLNVAL;15 if (file != NULL) {16 mask = DEFAULT_POLLMASK;17 if (file->f_op && file->f_op->poll)18 mask = file->f_op->poll(file, *pwait);19 mask &= fdp->events | POLLERR | POLLHUP;20 fput(file);21 }22 if (mask) {23 *pwait = NULL;24 (*count)++;25 }26 }27 fdp->revents = mask;28 }29}3)epoll
结构体
eventpoll->epitem->eppoll_entry->wait_queue_t
xxxxxxxxxx401struct eventpoll {2 //调用sys_epoll_wait时的阻塞队列3 wait_queue_head_t wq;4 //epoll事件的阻塞队列5 wait_queue_head_t poll_wait;6 struct list_head rdllist; //已准备好的事件7 unsigned int hashbits;8 //按页指向epitem.llink9 char *hpages[EP_MAX_HPAGES];10};11
12struct eppoll_entry {13 //插入epitem.pwqlist14 struct list_head llink;15 //指向epitem16 void *base;17 wait_queue_t wait;18 //指向eventpoll.wq19 wait_queue_head_t *whead;20};21
22struct epitem {23 //指向eventpoll.hpages24 struct list_head llink;25 //关联eventpoll.rdllink,表示epitem是以准备好事件26 struct list_head rdllink;27 //等待的eppoll_entry数量28 int nwait;29 //关联eppoll_entry.llink30 struct list_head pwqlist;31 //关联eventpoll32 struct eventpoll *ep;33 34 int fd;35 struct file *file;36 struct epoll_event event;37
38 //关联file.f_ep_links39 struct list_head fllink;40};sys_epoll_create
创建一个虚拟文件来表示epoll本身,设置文件的操作方法eventpoll_fops
xxxxxxxxxx41static struct file_operations eventpoll_fops = {2 .release = ep_eventpoll_close,3 .poll = ep_eventpoll_poll4};xxxxxxxxxx131asmlinkage long sys_epoll_create(int size)2{3 int error, fd;4 unsigned int hashbits;5 struct inode *inode;6 struct file *file;7 ...8 hashbits = ep_get_hash_bits((unsigned int) size);9 error = ep_getfd(&fd, &inode, &file); //一切皆文件,所以epoll本身也是一个文件10 error = ep_file_init(file, hashbits); //ep_init创建eventpoll并关联file->private_data = ep;11 ...12 return fd;13}sys_epoll_ctl
xxxxxxxxxx471asmlinkage long sys_epoll_ctl(int epfd, int op, int fd, struct epoll_event __user *event)2{3 int error;4 struct file *file, *tfile;5 struct eventpoll *ep;6 struct epitem *epi;7 struct epoll_event epds;8
9 if (copy_from_user(&epds, event, sizeof(struct epoll_event))) //复制到内核空间10 file = fget(epfd); //获取epoll文件11 tfile = fget(fd); //获取监听对象的file12 if (!tfile->f_op || !tfile->f_op->poll)13 goto eexit_3;14
15 if (file == tfile || !IS_FILE_EPOLL(file)) //自己监听自己、监听对象非epoll文件错误16 goto eexit_3;17
18 ep = file->private_data; //获取eventpoll19 epi = ep_find(ep, tfile, fd); //获取epitem,不为空表示对fd编辑20
21 switch (op) {22 case EPOLL_CTL_ADD: //添加23 if (!epi) {24 epds.events |= POLLERR | POLLHUP;25 error = ep_insert(ep, &epds, tfile, fd);26 } else27 error = -EEXIST;28 break;29 case EPOLL_CTL_DEL: //删除30 if (epi)31 error = ep_remove(ep, epi);32 else33 error = -ENOENT;34 break;35 case EPOLL_CTL_MOD: //修改36 if (epi) {37 epds.events |= POLLERR | POLLHUP;38 error = ep_modify(ep, epi, &epds);39 } else40 error = -ENOENT;41 break;42 }43 if (epi)44 ep_release_epitem(epi);45 return error;46}47
ep_find
xxxxxxxxxx181//ep事件、要监听的file、fd2static struct epitem *ep_find(struct eventpoll *ep, struct file *file, int fd)3{4 unsigned long flags;5 struct list_head *lsthead, *lnk;6 struct epitem *epi = NULL;7
8 lsthead = ep_hash_entry(ep, ep_hash_index(ep, file, fd));9 list_for_each(lnk, lsthead) {10 epi = list_entry(lnk, struct epitem, llink);11 if (epi->file == file && epi->fd == fd) {12 ep_use_epitem(epi);13 break;14 }15 epi = NULL;16 }17 return epi;18}ep_insert
xxxxxxxxxx311static int ep_insert(struct eventpoll *ep, struct epoll_event *event, struct file *tfile, int fd)2{3 int error, revents, pwake = 0;4 unsigned long flags;5 struct epitem *epi;6 struct ep_pqueue epq;7
8 epi = EPI_MEM_ALLOC() //创建一个epitem9 INIT_LIST_HEAD(&epi->llink); //初始化链表指向自己10 INIT_LIST_HEAD(&epi->rdllink);11 INIT_LIST_HEAD(&epi->fllink);12 INIT_LIST_HEAD(&epi->txlink);13 INIT_LIST_HEAD(&epi->pwqlist);14 epi->ep = ep;15 epi->file = tfile;16 epi->fd = fd;17 epi->event = *event;18
19 epq.epi = epi;20 init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);21 //同select、poll一样,加入22 revents = tfile->f_op->poll(tfile, &epq.pt);23
24 list_add_tail(&epi->fllink, &tfile->f_ep_links); //将epitem插入到file.f_ep_links中25 //将epitem关联到ep->hpages中26 list_add(&epi->llink, ep_hash_entry(ep, ep_hash_index(ep, tfile, fd)));27
28 if (pwake)29 ep_poll_safewake(&psw, &ep->poll_wait);30 return 0;31}ep_ptable_queue_proc
xxxxxxxxxx161static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead, poll_table *pt)2{3 struct epitem *epi = EP_ITEM_FROM_EPQUEUE(pt);4 struct eppoll_entry *pwq;5
6 if (epi->nwait >= 0 && (pwq = PWQ_MEM_ALLOC())) {7 init_waitqueue_func_entry(&pwq->wait, ep_poll_callback); //注册事件到达时回调方法,将epitem.rdllink插入到eventpoll.rdllink中8 pwq->whead = whead; //设置当前在哪里等待,即要监听的fd的sk->sk_sleep(1)9 pwq->base = epi;10 add_wait_queue(whead, &pwq->wait); //加入等待队列whead(2)11 list_add_tail(&pwq->llink, &epi->pwqlist); //将eppoll_entry插入epitem的pwqlist中(3)12 epi->nwait++; //epitem中关联的eppoll_entry数量13 } else {14 epi->nwait = -1;15 }16}ep_remove
xxxxxxxxxx281static int ep_remove(struct eventpoll *ep, struct epitem *epi)2{3 int error;4 unsigned long flags;5 struct file *file = epi->file;6 7 ep_unregister_pollwait(ep, epi); //从fd的等待队列中移除8 error = ep_unlink(ep, epi); //取消关联9 ep_release_epitem(epi); //回收epitem10 return error;11}12
13static void ep_unregister_pollwait(struct eventpoll *ep, struct epitem *epi)14{15 int nwait;16 struct list_head *lsthead = &epi->pwqlist;17 struct eppoll_entry *pwq;18
19 nwait = xchg(&epi->nwait, 0); //设置eppoll_entry数量为020 if (nwait) {21 while (!list_empty(lsthead)) {22 //ep_ptable_queue_proc(3)处23 pwq = list_entry(lsthead->next, struct eppoll_entry, llink);24 //ep_ptable_queue_proc(1、2)处25 remove_wait_queue(pwq->whead, &pwq->wait);26 }27 }28}sys_epoll_wait
xxxxxxxxxx151// epfd:epoll的fd,events:事件,maxevent:要返回的数量2long sys_epoll_wait(int epfd, struct epoll_event __user *events, int maxevents, int timeout)3{4 int error;5 struct file *file;6 struct eventpoll *ep;7 file = fget(epfd);8 // 看epfd是否为EPOLL9 IS_FILE_EPOLL(file)10 // 获取绑定的eventpoll11 ep = file->private_data;12
13 error = ep_poll(ep, events, maxevents, timeout);14 return error;15}ep_poll
xxxxxxxxxx281int ep_poll(struct eventpoll *ep, struct epoll_event __user *events, int maxevents, long timeout)2{3 int res, eavail;4 unsigned long flags;5 long jtimeout;6 wait_queue_t wait;7
8retry:9 res = 0;10 if (list_empty(&ep->rdllist)) { //准备好的事件为空11 init_waitqueue_entry(&wait, current); //创建一个wait_queue_t12 add_wait_queue(&ep->wq, &wait); //添加到ep->wq中13 for (;;) {14 set_current_state(TASK_INTERRUPTIBLE); //设置可中断15 if (!list_empty(&ep->rdllist) || !jtimeout) //如果在阻塞期间,事件完成,那么会在callback方法中将epitem.rdllist关联到ep->rdllist中,在此可break16 break;17 write_unlock_irqrestore(&ep->lock, flags);18 jtimeout = schedule_timeout(jtimeout); //超时阻塞19 }20 remove_wait_queue(&ep->wq, &wait); //移除21 set_current_state(TASK_RUNNING); //设置运行22 }23 eavail = !list_empty(&ep->rdllist);24 if (!res && eavail &&25 !(res = ep_events_transfer(ep, events, maxevents)) && jtimeout)26 goto retry;27 return res;28}ep_events_transfer
xxxxxxxxxx121static int ep_events_transfer(struct eventpoll *ep,struct epoll_event __user *events, int maxevents)2{3 int eventcnt = 0;4 struct list_head txlist;5
6 INIT_LIST_HEAD(&txlist);7 if (ep_collect_ready_items(ep, &txlist, maxevents) > 0) {8 eventcnt = ep_send_events(ep, &txlist, events);9 ep_reinject_items(ep, &txlist); //将数据链接到ep.rdllink中,list_empty(&ep->rdllist)就不会走10 }11 return eventcnt;12}ep_collect_ready_items
xxxxxxxxxx201static int ep_collect_ready_items(struct eventpoll *ep, struct list_head *txlist, int maxevents)2{3 int nepi;4 unsigned long flags;5 struct list_head *lsthead = &ep->rdllist, *lnk;6 struct epitem *epi;7
8 //获取准备好的数量9 for (nepi = 0, lnk = lsthead->next; lnk != lsthead && nepi < maxevents;) {10 epi = list_entry(lnk, struct epitem, rdllink);11 lnk = lnk->next;12 if (!EP_IS_LINKED(&epi->txlink)) {13 epi->revents = epi->event.events;14 list_add(&epi->txlink, txlist); //加入txlist15 nepi++; //数量16 EP_LIST_DEL(&epi->rdllink); //删除&epi->rdllink17 }18 }19 return nepi;20}ep_send_events
xxxxxxxxxx351int ep_send_events(struct eventpoll *ep, struct list_head *txlist, struct epoll_event __user*events)2{3 int eventcnt = 0, eventbuf = 0;4 unsigned int revents;5 struct list_head *lnk;6 struct epitem *epi;7 struct epoll_event event[EP_MAX_BUF_EVENTS];8
9 list_for_each(lnk, txlist) {10 epi = list_entry(lnk, struct epitem, txlink);11 revents = epi->file->f_op->poll(epi->file, NULL); //获取文件的准备好事件12 epi->revents = revents & epi->event.events; //合并事件13 if (epi->revents) {14 event[eventbuf] = epi->event;15 event[eventbuf].events &= revents;16 eventbuf++;17 if (eventbuf == EP_MAX_BUF_EVENTS) {18 if (__copy_to_user(&events[eventcnt], event,19 eventbuf * sizeof(struct epoll_event)))20 return -EFAULT;21 eventcnt += eventbuf;22 eventbuf = 0;23 }24 }25 }26
27 if (eventbuf) { //将内核的event复制到用户空间events中28 if (__copy_to_user(&events[eventcnt], event,29 eventbuf * sizeof(struct epoll_event)))30 return -EFAULT;31 eventcnt += eventbuf;32 }33
34 return eventcnt;35}